Math 37 - Lecture 26
Inference for Regression (10.1)
Goals:
(Is the presence of a relationship more than just by chance?)
Inference Have a population of bivariate observations, e.g. (#deaths, boat registrations) for all years, and have taken a sample. We can calculate a regression line for this sample data. What does this sample regression, ![]() =a+bx tells us about the true population regression line: E(y)=a+bx?
=a+bx tells us about the true population regression line: E(y)=a+bx?
The Regression Model - Each value of x defines a "subpopulation" (e.g. all the students who study 5 hours). We need to assume that these subpopulations have the same shape (normal) and standard deviation (s), but the mean depends on x (E(y)=a+bx).
Assume is a Linear relationship
Assume response variable has Normal distribution at each value of x.
Assume the variability about this line is Equal at each x value=s2
Don’t know a and b: take a sample and estimate them!
Estimates for the model parameters
- Suggest statistic (estimate computed from sample) for a + bx:
- Since a/![]() and b/
and b/![]() are statistics, their values vary from sample to sample.
are statistics, their values vary from sample to sample.
Sampling Distribution of ![]() :
:
Shape:
Center:
Standard deviation: SE(![]() ) = s/(sxsqrt(n-1)) (sx=Std Dev(x))
) = s/(sxsqrt(n-1)) (sx=Std Dev(x))
- To estimate s: use the sample standard deviation of the residuals=s
Inference for b:
Tests of significance:
For b: Hypothesis test: H0: b=0 (slope is horizontal)
Ha:b![]() 0(is a relationship),Ha:b>0(positive association) Ha:b<0(negative assoc)
0(is a relationship),Ha:b>0(positive association) Ha:b<0(negative assoc)
Test Statistic:
p-value (computer gives the two-sided p-value)
Confidence interval for b:
Inference for a: Same idea, but not used that often
Model Checking: Check the technical assumptions made
Examining the residuals helps assess how well the line describes the data and if the assumptions are met. Plot the residuals on vertical axis and explanatory variable on horizontal axis.
To save residuals, use MTB> regress c2 1 c1; SUBC> residuals c8.
-1.38274 4.99406 5.37197 -4.75068 1.37639 -2.49875 -9.24681
5.63275 1.38635 -2.23464 -0.10535 0.14880 2.65377 -1.34512
Residual Plots: Look for a pattern.
Want residuals to follow a Normal distribution, indicates that each subpopulation follows a Normal distribution.
Note - can often deal with violations, e.g. transformations
Example Interpret output for for Manatee and NBA data sets.
Not Covered: Prediction Intervals, nonlinear regression, 10.2, Ch. 11
Math 37 - Class Exercise
Example (2.25) One measure of running form is the "stride rate", the number of steps taken per second. A runner is inefficient when the rate is either too high or too low. As the speed increases, the stride rate should also increase. In a recent study, 21 of the best American female runners were timed and their speed (feet per second) and average stride rate were recorded:
|
Speed |
15.86 |
16.88 |
17.50 |
18.62 |
19.97 |
21.06 |
22.11 |
|
Stride Rate |
3.05 |
3.12 |
3.17 |
3.25 |
3.36 |
3.46 |
3.55 |
Below is a scatterplot and the summary statistics for these data:
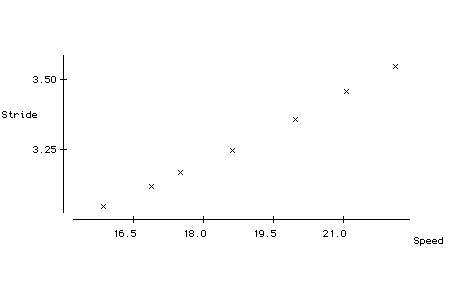
Mean 18.857 3.28 r=.999
Std Dev 2.2899 .18403
(a) Do you think a straight line adequately describes these data?
(b) Compute the slope and intercept for least squares line (3 places)
(c) For each of the speeds given, compute the predicted value for the stride rate using your least squares line. Use these values to compute the residuals. Verify that the residuals sum to zero.
(d) Sketch a plot of the residuals vs. speed. Describe the pattern. What does the plot indicate about the adequacy of the linear fit?
resids
0 speed
Just for fun, let's go ahead and run the regression: Here's the Minitab output:
The regression equation is Stride = 1.77 + 0.0803 Speed
Predictor Coef Stdev t-ratio p
Constant 1.76608 0.03068 57.57 0.000
Speed 0.080284 0.001617 49.66 0.001
s = 0.009068 R-sq = 99.8% R-sq(adj) = 99.6%
(e) How much of the variability in stride rate is explained by the speed of the runner?
(f) Is there sufficient evidence to conclude that the stride rate is indeed higher at higher speeds? (State H0 and Ha and the corresponding p-value to test these hypotheses.) Hint: How would you decide if speed and stride rate are related?